

Evaluating Audio AI LLM models (Part 1)
Part 1. Pink Beatles in a Purple Zeppelin
Part 2. Unnatural Selection
Part 3. Resilient
Citations & References included at the bottom of this article.
In this series, I aim to assess the functional use of cutting-edge LLM tools for Sound Design and Music Production. It is not my intent to ascribe a moral value to 'AI', Neural Nets, or LLM tools.
Part 1. Provides an introduction for the series.
Part 2. . Compares many prompts and popular models.
Part 3. Discusses model limitations and highlights to keep an eye on.
Meta/Facebook, Google, and a multitude of programmers are racing to develop AI Large Language Models (LLMs) capable of churning out high-quality Sfx and music.
Below, I compare the output from multiple LLMs across various prompts. This article features a comparison of three models trained for music and four models tailored for Sound Design.
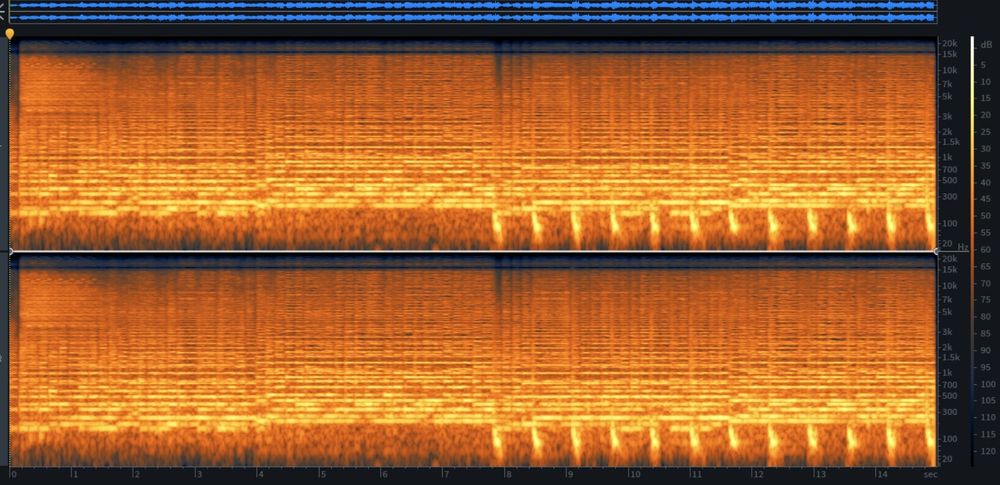
Output from three models trained for music with the prompt: 80s synth playing an arpeggio.
| Meta/Facebook - MusicGen [1] | Google MusicLM/Ai Test Kitchen [2] | Riffusion [3] |
|---|---|---|
|
|
|
Introduction & Preamble
Lurking around the digital sphere, it feels as if Pandora's box has been blown wide open with many riding waves into the unknown. The exponential development of neural networks, LLMs, and, more generally, 'AI' is changing our landscape.
In the 'early times' before the LLM revolution went fully public, I applied to closed-betas and joined a range of creatives and programmers exploring Dall-E, Midjourney, Stable Diffusion, Chat GPT, Google's AI Test Kitchen, and Riffusion.

Engaging in conversations about prompt engineering, I observed the advancement of users as inputs developed from sentence fragments, to paragraphs, to sophisticated pseudo markup languages with negative and positive weights.
Though developments in LLMs have raised concerns among artists and creatives [4], [5], [6], [7], the tools are now at our fingertips and it feels like the genie cannot be put back into its bottle. The tools are here, and they aren't going away. With caution, I am curious to understand the capabilities of these tools, and the limitations of our genies.
Sound Design
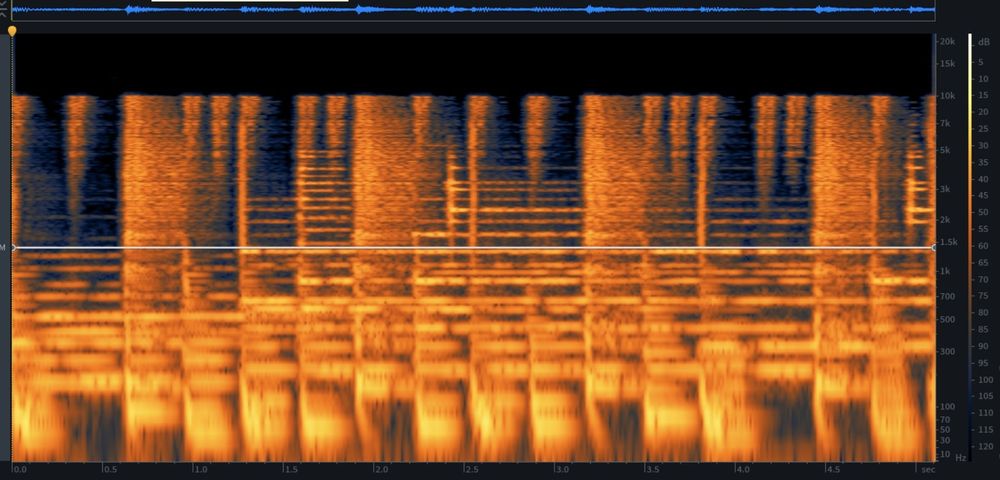
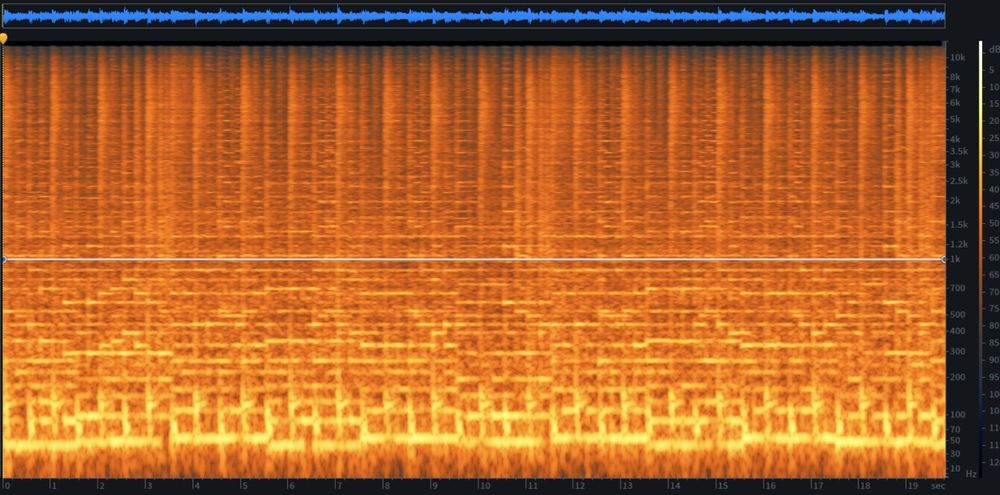
A comparison of four Sound Design focused models with the prompt: Roar Of An Undead Ice Mammoth
| AudioGen Plus [8] | AudioLDM 2 Spectrogram [9] | Bark [10] | Tango [11] |
|---|---|---|---|
![Spectrogram for the audio produce by [] from the prompt: 80s synth playing an arpeggio.](https://ambientartstyles.com/content/images/size/w1000/2023/08/Roar-of-an-undead-ice-mammoth_audiogen-plus_Aug-2023-Spectrogram.jpg)
|
![Spectrogram for the audio produce by [] from the prompt: 80s synth playing an arpeggio.](https://ambientartstyles.com/content/images/size/w1000/2023/08/Roar-of-an-undead-ice-mammoth_Audio-LDM2_Aug-2023-Spectrogram.jpg)
|
![Spectrogram for the audio produce by [] from the prompt: 80s synth playing an arpeggio.](https://ambientartstyles.com/content/images/2023/08/Roar-of-an-undead-ice-mammoth_Bark_Aug-2023-Spectrogram.jpg)
|
![Spectrogram for the audio produce by [] from the prompt: 80s synth playing an arpeggio.](https://ambientartstyles.com/content/images/size/w1000/2023/08/Roar-of-an-undead-ice-mammoth_Tango_Aug-2023-Spectrogram.jpg)
|
Using the Youlean Loudness Meter [12], I found AudioLDM 2's screechy output to peak at +0.3 dB (true peak) and +1 LUFS (short-term). For the LDM2 upload above, I added a fade-in and considerably reduced the loudness. The other model outputs were not modified in any way.
It is curious that the two outputs of highest quality (AudioGen Plus and Tango) exhibit the most prominent limitations in terms of Hz. AudioGen Plus appears to have a hard cutoff around 7k Hz, similar to Tango's cutoff. For loudness, AudioGen Plus peaks slightly below -13 LUFS ( -2.8 db true peak), with Tango (-8.2 db true peak) and Bark's being noticeably softer.
The output from these models is greatly influenced by each model's training data. By systematically analyzing diverse prompts and outputs, we can uncover specific targeted responses and gain insights into the capabilities of these models.
In Part 2 of this series, you'll find a variety of prompt-output comparisons, clear methods, and a deeper analysis and for these as well as other models.
Afterword
I feel apprehension toward my craft, and believe this to be another technological revolution which is here to stay. Reading through threads, discord conversations, and papers, I keep coming back to two quotes,
"It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change." - A Darwin misquote.
Human-machine collaboration is the future - Garry Kasparov
What I know for certain is that:
- I possess an extraordinary audio library and recording capability, and have access to software that affords me tremendous flexibility in crafting audio.
- I have a deep passion for this artistic pursuit; for harmonizing and pairing audio with both linear and non-linear media. While it is work, it is fun and rewarding.
- While these tools are powerful, they do have limitations. (expanded in Part 3).
References
Spectrograms were created using iZotope RX9.
[1] Copet, Jade, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. “Simple and Controllable Music Generation.” https://doi.org/10.48550/ARXIV.2306.05284.
[2] Agostinelli, Andream, Timo Denk, Zalán Borsos, Jesse Engel, Maura Verzetti, Antoine Caillon, et al. 2023. “MusicLM: Generating Music from Text.” ArXiv.Org. January 26, 2023. https://arxiv.org/abs/2301.11325.
[3] Riffusion. n.d. GitHub. https://github.com/riffusion.
[4] Girotra, Karan, Lennart Meincke, Christian Terwiesch, and Karl T. Ulrich. 2023. “Ideas Are Dimes a Dozen: Large Language Models for Idea Generation in Innovation.” SSRN Electronic Journal. https://doi.org/10.2139/ssrn.4526071.
[5] Shen, Yongliang, and Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang. 2023. “HuggingGPT: Solving AI Tasks with ChatGPT and Its Friends in Hugging Face.” ArXiv.Org. https://arxiv.org/abs/2303.17580.
[6] Obedkov, Evgeny. 2023. “NCSoft Launches VARCO Studio, GenAI Platform with Various Models for Creating Texts, Images, and Digital Humans | Game World Observer.” Game World Observer. August 17, 2023. https://gameworldobserver.com/2023/08/17/ncsoft-varco-llm-ai-tools-texts-images-digital-humans.
[7] Broderick, Ryan. 2023. “WGA Writers’ Strike over AI, ChatGPT Has Higher Stakes than You Think.” Polygon, May 31, 2023. https://www.polygon.com/23742770/ai-writers-strike-chat-gpt-explained.
[8] Kreuk, Felix, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. 2022. “AudioGen: Textually Guided Audio Generation.” https://doi.org/10.48550/ARXIV.2209.15352.
[9] Liu, Haohe, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. 2023. “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.” https://doi.org/10.48550/ARXIV.2301.12503.
[10] Bark, Suno-ai, Riffusion. n.d. GitHub. https://github.com/suno-ai/bark.
[11] Ghosal, Deepanway, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. 2023. “Text-to-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model.” https://doi.org/10.48550/ARXIV.2304.13731.
[12] Youlean Loudness Meter - Free VST, AU and AAX Plugin. 2023. Youlean. August 22, 2023. https://youlean.co/youlean-loudness-meter/.

